
Do I need an agent?
AI
Can I just use ChatGPT?
I often get asked two questions that are more connected than they seem:
- “Should I just paste my data into ChatGPT and ask for analysis, or do I need something more?”
- “What even are agents?”
The answer to the first question actually leads pretty naturally to the second. So let’s start there.
Let’s say you’re tasked with analyzing product reviews. You might think: just paste them into ChatGPT and let it work its magic. For a basic, one-off analysis, this is usually fine and even offers a lot of ad hoc flexibility.
The downsides of this are that the ChatGPT is always working from scratch, it doesn’t always show its work reliably, and everything lives and dies in that conversation. You’re also limited by how much text the AI can process at once (Context Window size limits), and when conversations get very long, the AI tends to lose track of earlier instructions or details.
In contrast, a structured data system, which can be as simple as a MS Copilot Notebook or Google NotebookLM, to as advanced as a customized vector database, allows for permanent storage and more control over the agent working with the data.
Once your data lives in a structured system, you’ve also created an ideal playground for agents and agent “tools”.
(Side note: You might be thinking—doesn’t ChatGPT use tools, search the web, and run code? Is it an agent? Yes, it is. A testament to the value of agents!)
What is an agent?
To understand what an agent is, it helps to compare it to a plain LLM.
LLM: You ask a question → it predicts an answer → done. (This is how most queries are answered by ChatGPT)
Agent: You provide an end-goal and a list of tools (run a web search, query a database, read files…) → it picks from available tools → it acts, observes, adjusts → repeats until the goal is met.
An LLM is like a brilliant advisor with no cell reception who can only give instructions from memory. An agent is that same advisor with access to a browser, your company’s database, your files, or whatever other tools you give it.
OK… so what does an agent look like?
Note: the purpose of this demo is not to build a system that beats ChatGPT’s output for this one-off task, but to illustrate what an agent is. For this generic example task, ChatGPT would beat this system running on my laptop, but if you wanted verifiability, repeatability, advanced NLP (natural language processing) or a large dataset, ChatGPT’s chat window alone quickly becomes the wrong tool for the job.
Let’s build on the product review example with a simple demo: building structured data from a list of product reviews, and then having an agent analyze it using txtai, an open-source AI framework.
For our dataset, I pulled 200 negative Crocs reviews from Kaggle. We’ll embed the reviews (convert them into numerical representations that capture their meaning), cluster them by semantic similarity (group reviews that are about similar things), and then give an agent some tools to analyze the structured data.
All of this will be run on a MacBook Air using a tiny local LLM (4 billion parameters). You could expect much stronger results from a production system using a proper foundational model (>300 billion parameters).
-
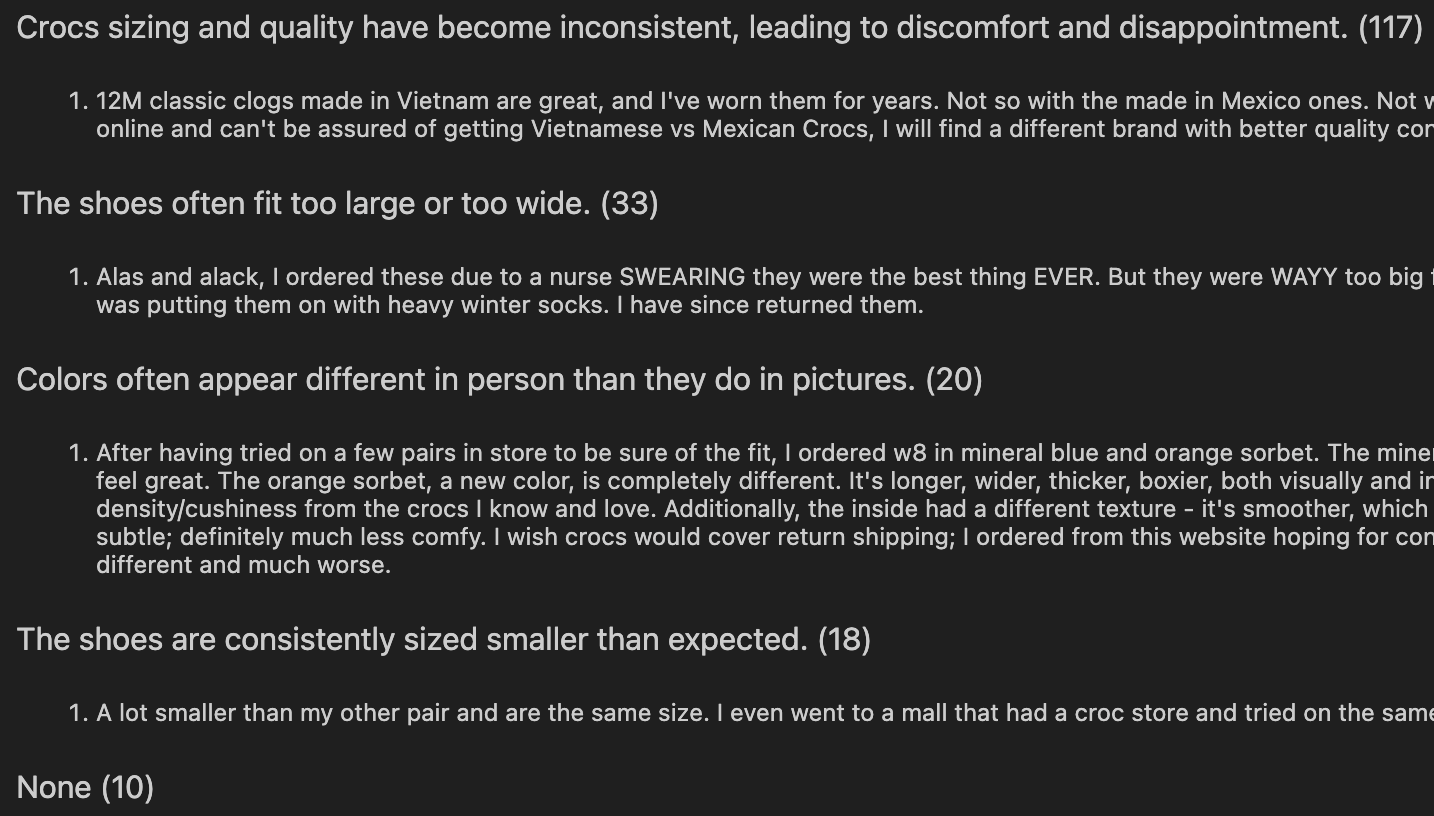
First, let’s store and cluster the reviews by semantic similarity using txtai’s built-in similarity graph, then have an LLM label each cluster.
Below are the results: each cluster’s label, review count, and a sample from the raw data.
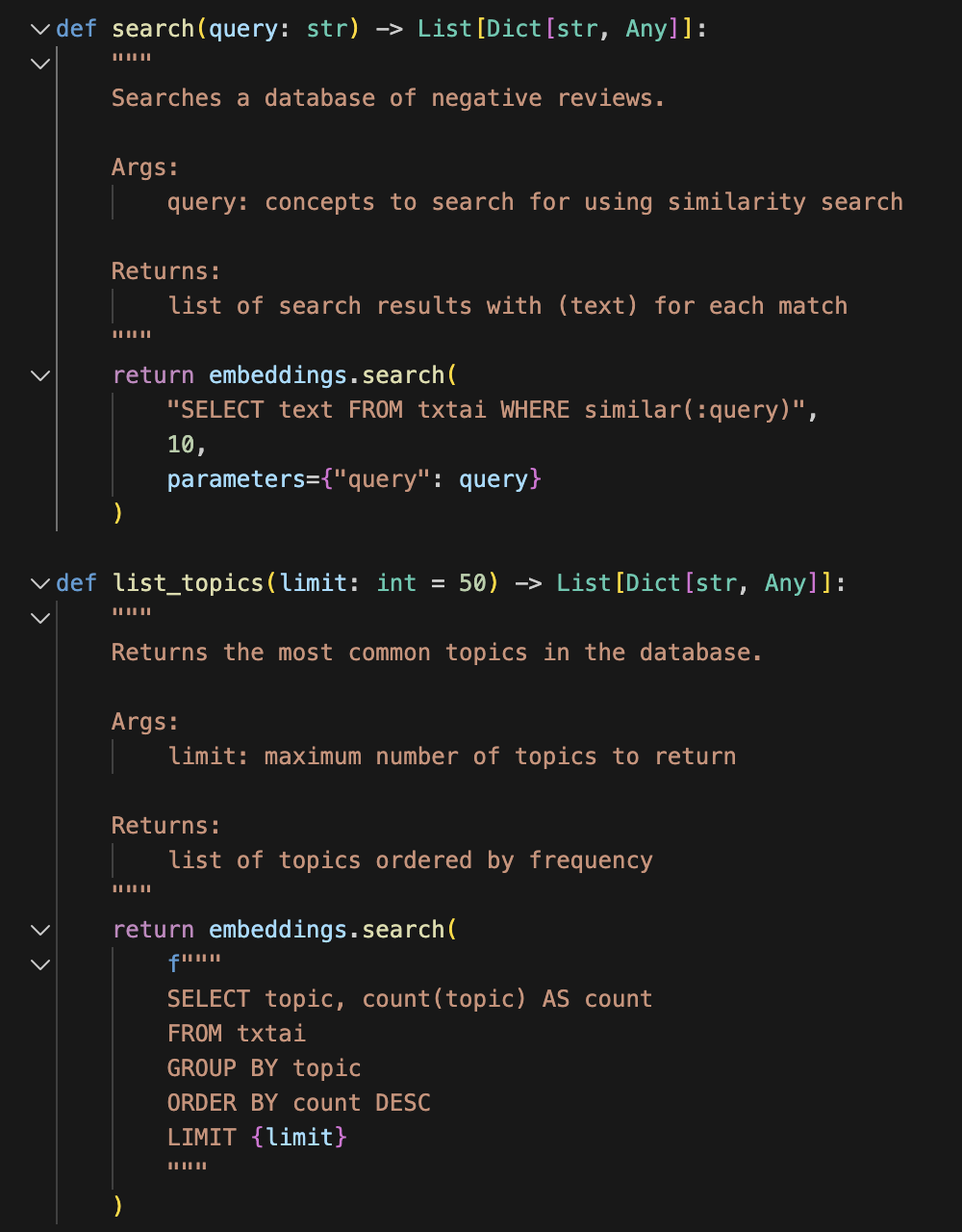
- Now let’s give an agent two tools to use to analyze the data. We’ll give it one tool to read the cluster labels (“list_topics”) and one tool to query the reviews in the dataset (“search”). Don’t worry if Python isn’t your first language (or second, or third). All you need to know is that the code below defines two tools and tells the agent how to wield them.
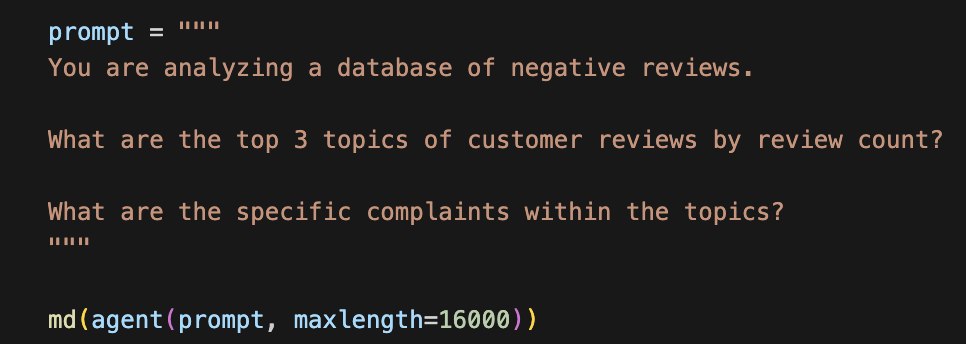
- Now let’s give the agent a goal. We’ll ask it to find the most common topics in the dataset and to provide specific complaints within each topic.
 4. Next we observe how the agent chooses to use the tools to answer the question.
First the agent identifies the top 3 clusters of review topics using the “list_topics” tool.
4. Next we observe how the agent chooses to use the tools to answer the question.
First the agent identifies the top 3 clusters of review topics using the “list_topics” tool.




- Finally, let’s see what the agent concluded from its data analysis using the two simple tools we gave it.
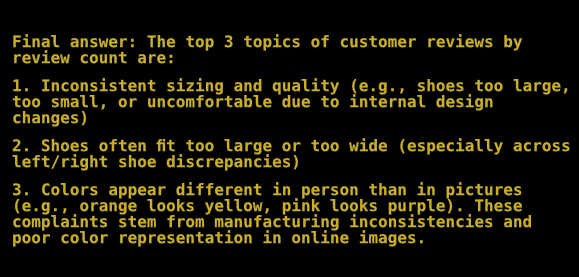
1. Inconsistent sizing and quality (e.g., shoes too large, too small, or uncomfortable due to internal design changes)
2. Shoes often fit too large or too wide (especially across left/right shoe discrepancies)
3. Colors appear different in person than in pictures (e.g., orange looks yellow, pink looks purple). These complaints stem from manufacturing inconsistencies and poor color representation in online images.
Epilogue: It took me a while to wrap my head around why anyone would use agents instead of just manually coding sequential calls to an LLM API. For me, the big unlock to understanding agents was better understanding what “tools” are and how they’re provided to the agent. Giving an agent a list of tools and some freedom to think for itself provides a lot of flexibility not found in traditional computer programs, which require instructions for how to handle every scenario. I hope this example helps illustrate this.